2 spots available
Comment réaliser un Retrieval-Augmented Generation (RAG) basique en Python
14 déc. 2024
Comment réaliser un Retrieval-Augmented Generation (RAG) basique en Python
Introduction
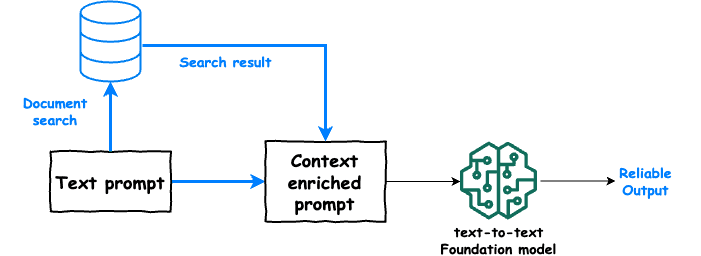
Le Retrieval-Augmented Generation (RAG) est une technique innovante qui combine la puissance des modèles de génération de texte avec des systèmes de récupération d'informations. Cette approche permet d'améliorer la qualité des réponses générées en intégrant des données externes pertinentes. Dans cet article, nous allons explorer comment mettre en œuvre un modèle RAG basique en Python, en utilisant des bibliothèques populaires comme Hugging Face Transformers et FAISS.
Qu'est-ce que le Retrieval-Augmented Generation ?
Le RAG fonctionne en deux étapes principales :
Récupération d'informations : Le modèle recherche des documents pertinents dans une base de données ou un corpus de texte en fonction d'une requête donnée.
Génération de texte : Une fois les documents récupérés, un modèle de génération de texte (comme GPT-3 ou BART) utilise ces informations pour produire une réponse plus précise et contextuelle.
Cette méthode est particulièrement utile dans des applications comme les chatbots, les assistants virtuels, et les systèmes de questions-réponses.
Prérequis
Avant de commencer, assurez-vous d'avoir installé les bibliothèques nécessaires. Vous pouvez le faire en exécutant :
pip install transformers faiss-cpu torch
Étape 1 : Préparer le corpus de documents
Pour cet exemple, nous allons créer un petit corpus de documents. Vous pouvez le remplacer par un ensemble de données plus vaste selon vos besoins.
Étape 2 : Indexer les documents avec FAISS
FAISS (Facebook AI Similarity Search) est une bibliothèque efficace pour la recherche de similarité. Nous allons l'utiliser pour indexer nos documents.
Étape 3 : Récupérer les documents pertinents
Nous allons maintenant écrire une fonction pour récupérer les documents les plus pertinents en fonction d'une requête.
Étape 4 : Générer une réponse
Nous allons maintenant utiliser un modèle de génération de texte pour produire une réponse basée sur les documents récupérés.
Conclusion
Dans cet article, nous avons exploré les étapes de base pour mettre en œuvre un système de Retrieval-Augmented Generation en Python. En combinant la récupération d'informations avec la génération de texte, nous pouvons créer des applications plus intelligentes et contextuelles. Bien que cet exemple soit simplifié, il peut être étendu avec des modèles d'embeddings plus avancés et des corpus de données plus riches pour des résultats encore meilleurs.Pour aller plus loin, vous pouvez explorer des modèles pré-entraînés sur des tâches spécifiques ou intégrer des bases de données plus complexes pour la récupération d'informations. Si vous souhaitez approfondir vos connaissances en informatique, n'hésitez pas à consulter notre page de formations en informatique.
Ressources supplémentaires
En espérant que cet article vous ait été utile pour comprendre et mettre en œuvre un système RAG basique en Python !
